 Ad Lagendijk
8 November 2009
Ad Lagendijk
8 November 2009
Where are your error bars?
Tags: climate model, error bars, global warming, model, reproducibility, scenario, variabilityPosted in Ethics, Getting published, Tips
Experimental observations always are coming with uncertainties. Any measurement is an estimate of the real value, if indeed such an objective value exist.
The uncertainty in the magnitude of a measured quantity is more important as the value itself. Many readers will find this remark alarming. The determination of the “error bars” is considered a dull, redundant exercise. Especially when the reported observable quantity has a surprising value that reporting it without the associated uncertainty will certainly get the authors the attention of the media, or get their manuscript accepted in Nature or Science.
The problem with a reported observable without an uncertainty is that people, including the reporting scientists, will draw conclusions from these observations that are in no way corroborated by that experiment.
Problematic example: temperature rise
Suppose an observable quantity depends on a parameter that can be varied in the experiment. A standard situation for showing the results is a simple X-Y plot. I will use as my example the observation of a temperature (in degrees Celsius) as function of time (in years). Imagine that the temperature I am plotting reflects a crucial parameter in a hot discussion on the climate. In the figure below I have depicted in red (imaginary) data points and a blue line representing a linear fit to the data. The fit seems very good and indeed the resulting slope has the reliable value of (1.44 ± 0.27) °C/year. Both the experimentalist and the environmental activists will be happy when they see this figure: the temperature will seriously rise in the future. Alarming press releases are cooked up and sent out. Alarm bells will ring. Head lines in the newspapers: “Earth will burn”.

But look at the graph below, where I have added the (imaginary) error bars. A very simple least-square fit to the data with a straight line gives the blue line:

The slope is this time (0.08 ± 0.31) °C/year. This honest approach to the data does not show a serious rate of increase of the temperature, but a modest dull behavior. Newspapers and the Greenpeace will be disappointed. Nature will send you their standard rejection text. And all of a sudden competitors will question the validity of your data. The community does not like party poopers.
Implicit size of error
Reporting your results in numbers in stead of graphs can bring you into an awkward situation if you want to stay away from reporting uncertainties. You have to make a choice on how many digits you are going to show. And this number implies you have to reveal something of your experimental uncertainty. If you publish that an observed quantity has a numerical value of 0.61, you are implicitly saying that that the digit 1 in 0.61 is significant and that your error in your result is somewhat like 0.61 ± 0.01, but certainly not 0.61 ± 0.10, in which case you should have reported 0.6 ± 0.1 as your answer.
Implicit reporting of the sizes of the error bars in a graph occurs when people say that the size of the symbols in the plot reflect the error bars. If this is the truth it is fine, but it it should be reported in each figure caption. And often the scatter of the various data points seems to imply that the error bars are much larger than the symbol sizes.
Too many error bars
For a number of trivial parameters error bars are not necessary. Especially if they do not influence, or are incorporated in, the error bars of already reported quantities. If the error bars clutter your plot you can show only a few error bars so that people can reliably predict the sizes of the intermediate error bars.
How difficult to determine error bars
To find the statistical errors is less difficult as people think. If the reported value is an average of a number  of observations, the averaging procedure already gives the error bars.
of observations, the averaging procedure already gives the error bars.
More difficult is the determination of the systematic errors. If you are using a ruler that is shrunk your observations are distorted. Here calibration is important. Estimate your systematic errors and if you fear that they are larger than your statistical errors at least report this feeling. Or do not publish your data.
Uncertainties in computer simulations
Everybody with some kind of science education can do simulations on a computer. In contrast to real experiments the so-called “numerical experiments” are always successful. There is never equipment that breaks down, samples that get burned. So many times failed experiments are replaced by successful simulations and the student will get his Ph.D. anyway.
Numerical scientific calculations are always done on the verge of what is possible with state of the art computers. So these calculations use massive computer power and run for a long time, days or weeks is not uncommon. But also in this case error bars should be reported. I do not trust numerical simulations where no error bars are shown.
Model or scenario
A good scientists uses models. if the models are too complicated to solve analytically one resorts to numerical simulations based on random number generators. You run the program several times with the same input, but with different random number seeds, and compare the variation in the output. Period.
But what if the program runs for a long time (like weeks) and there are many parameters to vary? What do you do? You run it with a number of “reasonable” inputs. And you call this a scenario. If your outcome tells you that the Earth will burn, you stop calculating and you submit to Science. If you do not like the outcome you run it again with a different set of “reasonable” parameters. In jargon this is called a new “scenario”. You might even include several of the scenario’s in your paper (“worst case”, “optimistic”, …). But as you cannot cover a substantial part of the parameter space this selection of a few scenarios is ambiguous and dangerous. If you are honest you report in much more detail how much your simulation results depend on the initial conditions.
Three-dimensional plots
 My favorite plot is a simple X-Y plot. It shows many details, but also trends and easily allows for inclusion of error bars. These fantastic colorful high-dimensional plots that are supposed to give you more insight, hardly ever do. But two things are clear: (i) it is very difficult to show error bars in these plots, and (ii) the comparison between theory and experiment looks always better than when plotted in an X-Y plot. I fear that these two negative aspects are the very reasons these plots are so popular. Nasty questions by referees and readers are prevented.
My favorite plot is a simple X-Y plot. It shows many details, but also trends and easily allows for inclusion of error bars. These fantastic colorful high-dimensional plots that are supposed to give you more insight, hardly ever do. But two things are clear: (i) it is very difficult to show error bars in these plots, and (ii) the comparison between theory and experiment looks always better than when plotted in an X-Y plot. I fear that these two negative aspects are the very reasons these plots are so popular. Nasty questions by referees and readers are prevented.
Reluctance
My experience is that when I am listening to a talk and I ask the presenter to explain to me the absence error bars in the graphs, the presenter considers this to be a motion of distrust and an insult. I recently asked this question in a meeting of astronomers and again in a meeting of exploration engineers. In both cases the reactions were that of irritation. I do not understand this reluctance to reporting error bars. It belongs to the heart of natural science
To PhD students
Please realize the importance of error bars right from the start. Tailor your experiments and your daily practice in such a way that you know the experimental uncertainties and report them. Even on very preliminary graphs in lab journals. That is much better science than adding in your graphs an extra one or two parameters and show these colorful two-dimensional and three-dimensional colorful, sexy stuff.
 Follow
Follow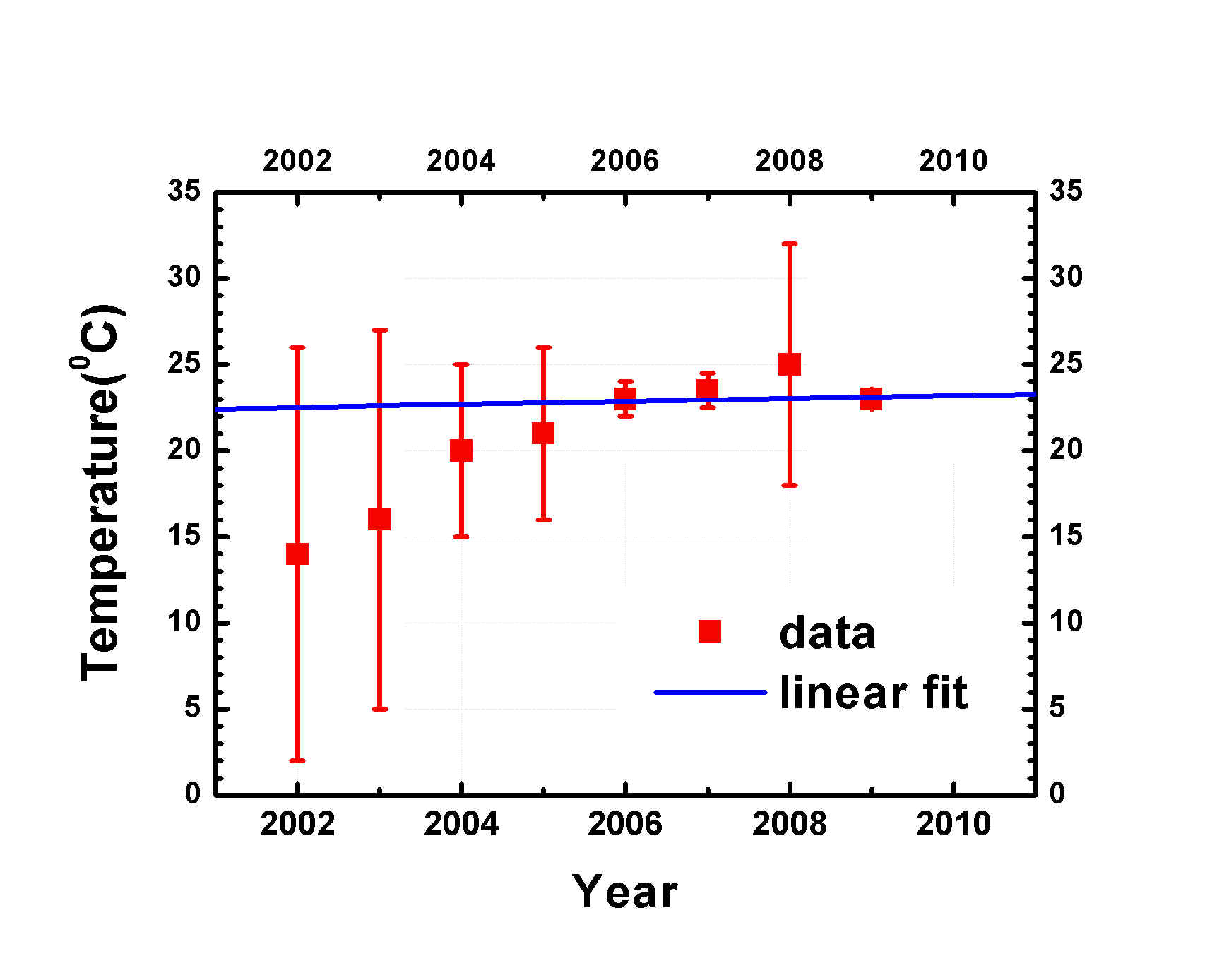{kind=link}
9 Nov 2009 18:41, Nicole de Beer
Thanks for bringing this topic once again to the attention of (young and aspiring) scientists. A book that helped shape my view of graphs and tables, and how misleading these can be, is Darrell Huff’s “How to lie with Statistics.” Originally published in 1954, but still valid, unfortunately.
9 Nov 2009 21:33, Ad Lagendijk
Nicole,
thanks for your reaction. I have the book. My edition is a Pelican from 1973. On page 21 there is a very nice cartoon (by Mel Calman), where we see the hand of a Superior Being pointing at a little man, while the Superior Being shouts “You’ve been CHOSEN to be a random sample!”
—
The book that my students use for learning about error bars is Data Reduction and Error Analysis for the Physical Sciences by Philip Bevington and D. Keith Robinsont (McGraw-Hill, 2003)
10 Nov 2009 8:36, Mirjam
In the case of PhD students I also see a responsibility of the supervisor here, who should train them to do things properly. Further, I’d say that statistics and error analysis should be a standard part of any university curriculum (at least in the sciences, but it wouldn’t hurt other people either – see the current hysteria about a certain flu). And would there be a way to make editors more aware of this issue? Finally, I’d like to point out that the situation may be even more complex when the results are qualitative and can’t be expressed as a simple number: do you pick the image that shows what things most often look like or do you pick the nicest one to show most clearly what you wanted to demonstrate. A famous example is a picture of a ‘monodisperse particle’… (fortunately, polydispersity can be easily expressed in a number and
a picture shouldn’t be taken as proof).
10 Nov 2009 16:09, Ad Lagendijk
Mirjam, thanks for the reaction.
Editors should educate referees and referees should educate editors. I notice that even in high-impact journals data are regularly reported without an error analysis.
10 Nov 2009 22:35, Klaas Wynne
I find that most data analysis packages will calculate errors in fit parameters while ignoring correlations between the parameters. In your example, the value of the slope is almost certainly correlated to the value at x=0 and that means that the error estimation is very much too small. Understanding these things requires one to actually read a statistics book properly (such as Bevington) but I find that the vast majority of scientist I know have no clue about statistics whatsoever. Some of my physics/chemistry colleagues (they shall remain nameless) don’t even use least squares analysis! The only reason this sort of bad behaviour works in the physical sciences is because you can repeat experiments many many times, which weeds out the completely rubbish crap. You can’t do that in medicine, sociology, etc., which is why they tend to get more proper statistics courses (is my impression). Medical people at least tend to employ statisticians (see, e.g., http://www.wynneconsult.com/root/HomePageKB01.htm).
12 Nov 2009 20:20, Jan
@Klaas.
Frankly, I have quite the opposite impression. There is a reason why physicists rarely use “correlations” in the sense that you mean. The reason is that correlation itself rarely gives you any insight. In addition, if you don’t have the data basis, then you don’t have a data basis – no “clever” statistical tool will make your results better.
By the way, I’ve recently read a scary article on the (mis)use of statistical analysis in economics: http://www.deirdremccloskey.com/docs/pdf/Article_190.pdf
Scary indeed.
16 Nov 2009 2:25, Alejandro Montenegro-Montero
A few years ago, The Journal of Cell Biology published an article entitled “Error bars in experimental biology” (The Journal of Cell Biology, Vol. 177, No. 1, 7-11), which highlights the “statistics” problem among scientists in the field.
From the abstract:
Error bars commonly appear in figures in publications, but experimental biologists are often unsure how they should be used and interpreted